Scraping IMDb Top 250 Data
The Internet Movie Database (IMDb) stores data about movies, including ratings, actors, directors etc. One of their famous lists is the Top 250 Movie List, showing the movies that received most appraisal and positive ratings.
IMDb offers an API, too, but it is not openly accessible, so I decided to write a webscraper as little project back in
January 2023 - to be run every night to track changes and developments in the list. The initial version was a basically
only using Python’s requests to load the page and beautifulsoup to extract elements from the HTML page
(cf. here).
Webscrapers, however, only continue work as long as the page design does not change - what actually happend to the IMDb website in June 2023. The new design looks more modern but I like the old one more because it is more clearly arranged - or this is simply what I was used to and I do not like to change…
Old design:
New design:

With the new page design, the webscraper needed an update. Additionally, the site now contains dynamic content. For
example, by clicking on the “detailed view” button, we can also see the rating count - something that was easily
accessible before. This is why I had to implement selenium in order to interact with the site programmatically. Also,
the content is not loaded all at once, so I also had to include the funtionality to scroll right down to the end of the
page.
# Set Firefox webdriver
options = Options()
options.add_argument("--headless")
options.set_preference('intl.accept_languages', 'en-US, en')
driver = webdriver.Firefox(options=options)
# Request page
driver.get('https://www.imdb.com/chart/top/')
# Select detailed view
driver.find_element(By.ID, 'list-view-option-detailed').click()
# Scroll to bottom of the page due to dynamic page loading
last_height = driver.execute_script("return document.body.scrollHeight") # Get scroll height
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Scroll down to bottom
time.sleep(0.5) # Wait to load page
new_height = driver.execute_script("return document.body.scrollHeight") # Calculate new scroll height and compare with last scroll height
if new_height == last_height:
break
last_height = new_height
soup = bs4.BeautifulSoup(driver.page_source, 'html.parser')
With the resulting data, I can again go ahead and retrive the most interesting data. Here is some stuff you can do with the data. First, we can plot year by rating count:
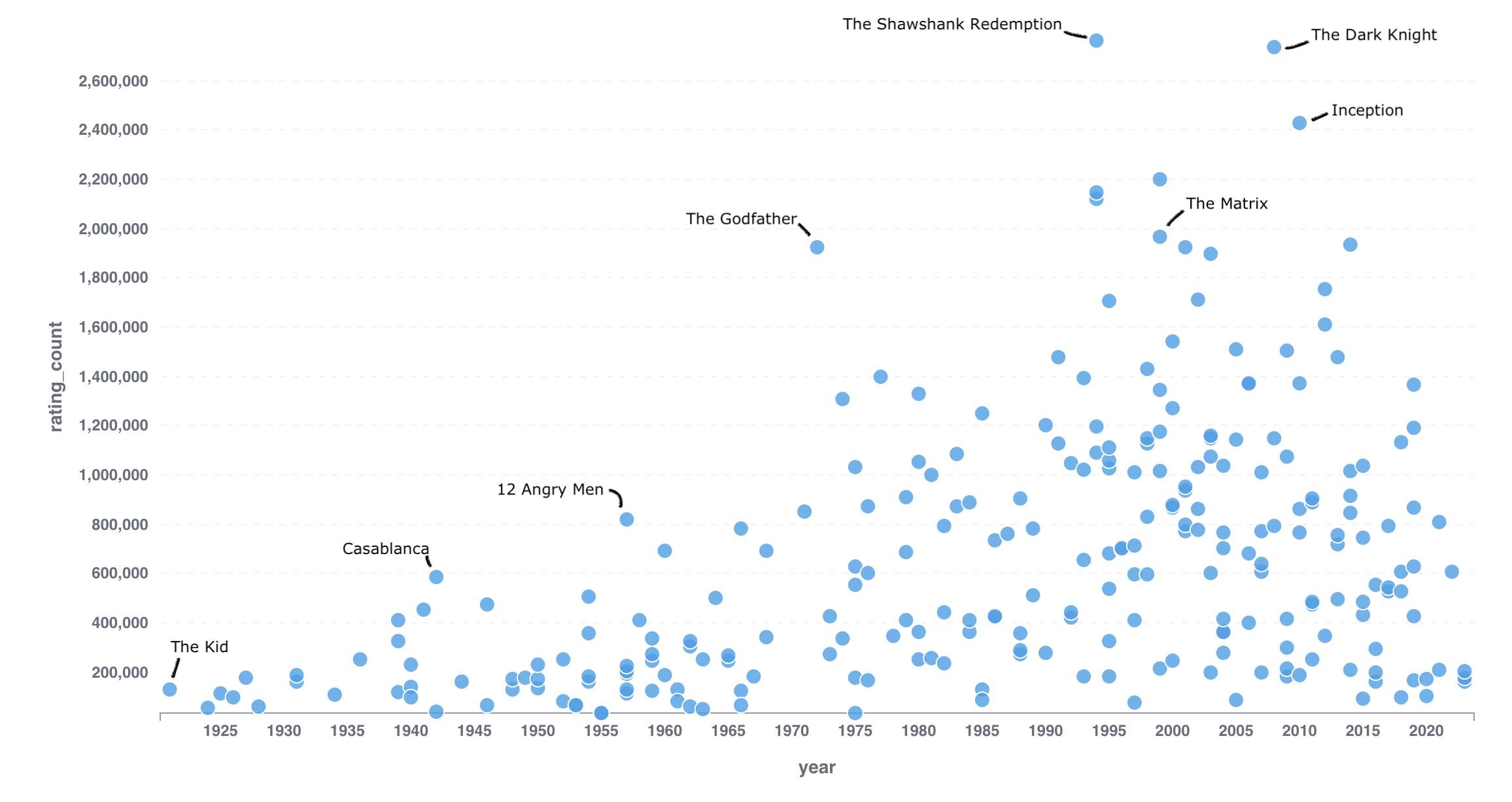
You can clearly see that newer movies tend, not surprisingly, to have more ratings. “The Shawshank Redemption”, which is also leading the Top 250 list, has most ratings, closely followed by “The Dark Knight”. There are some outliers such as “The Godfather” that has received lots of ratings despite its age.
When looking at the changes over time, the list is actually quite stable. Movies that moved up most are “Dead Poets Society” (from 206 to 200)and Ikiru (from 104 to 98) - which is related to the 2022 remake Living. Among the movies losing places are “Stand by Me” (from 215 to 223) and Groundhog Day (from 224 to 232).
In the first half of 2023, only 3 movies made it really into the list: “John Wick: Chapter 4”, “Guardians of the Galaxy Vol. 4”, and “Spider-Man: Across the Spider-Verse”. There is an interesting trend of gaining lots of places first due to lots of attention and a high number of new ratings, but then ending in a slow, and then pretty quick drop:
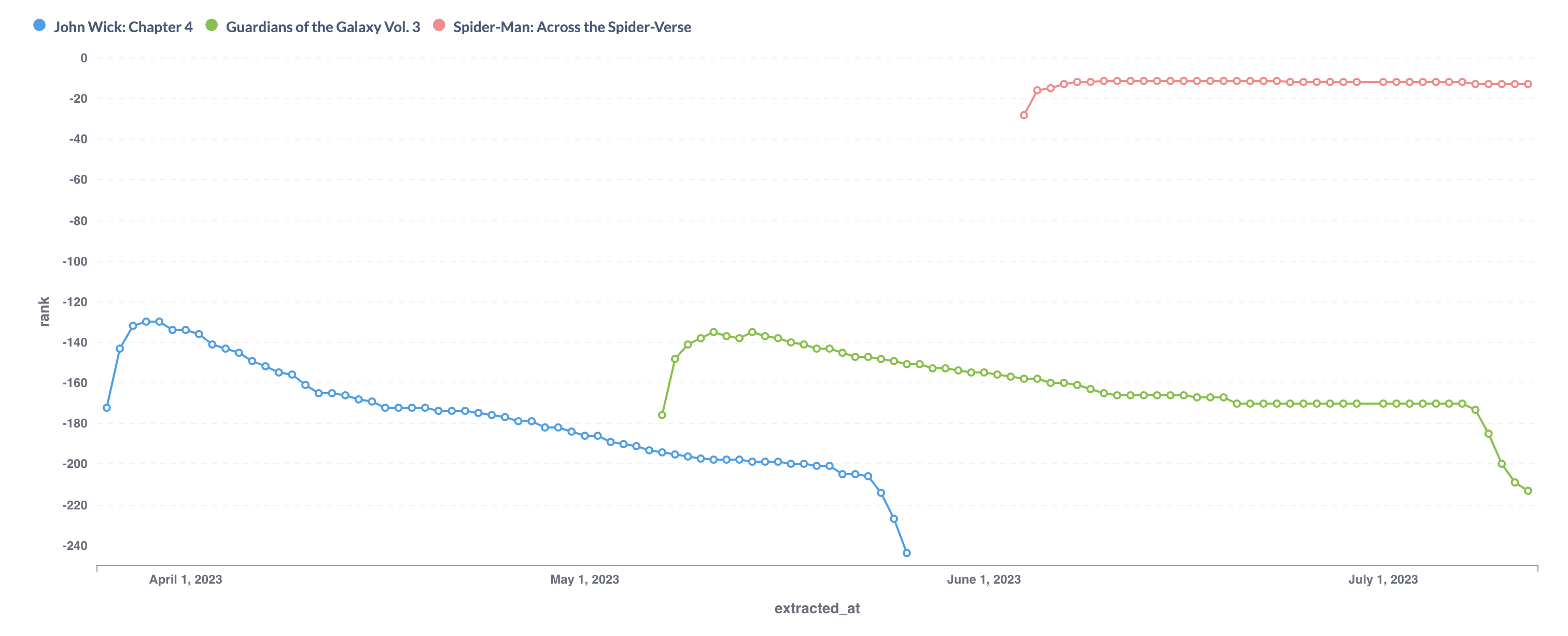
I’m curious to see what else interesting can be found in the data.